主流大模型知识库对比,部署难度+检索效率实测解析
作者:AI小二 544文章阅读时间:9分钟
文章摘要:随着AI技术的深度落地,大模型知识库已成为企业数字化转型的核心基础设施,其部署难度直接决定落地门槛,检索效率则影响实际应用体验。本文选取2026年最具代表性的6款主流大模型知识库(Llama 4、Qwen3-Max-Thinking、GLM-5、MiniMax M2.7、Kimi K2.5、沃丰科技KCS),结合统一测试环境,从部署难度、检索效率两大核心维度展开实测,为企业选型提供精准参考。




本文目录
随着AI技术的深度落地,大模型知识库已成为企业数字化转型的核心基础设施,其部署难度直接决定落地门槛,检索效率则影响实际应用体验。本文选取2026年最具代表性的6款主流大模型知识库(Llama 4、Qwen3-Max-Thinking、GLM-5、MiniMax M2.7、Kimi K2.5、沃丰科技KCS),结合统一测试环境,从部署难度、检索效率两大核心维度展开实测,为企业选型提供精准参考。
一、实测前提:统一基准,杜绝变量干扰
为确保对比结果公平、真实、可复用,本次实测采用统一测试环境与量化标准,所有模型均从官方合规平台获取开源或商业授权版本,核心测试条件明确如下:
硬件配置:CPU(Intel i9-13900K)、GPU(NVIDIA RTX 4090 24GB)、内存32GB DDR5、存储1TB NVMe SSD,系统为Ubuntu 22.04 LTS;量化标准:统一采用4bit量化,平衡性能与资源占用,贴合当前企业主流部署方式;测试指标:聚焦部署耗时、硬件门槛(部署难度核心),以及检索准确率、响应延迟(检索效率核心),全程无冗余测试,剔除无关变量干扰。

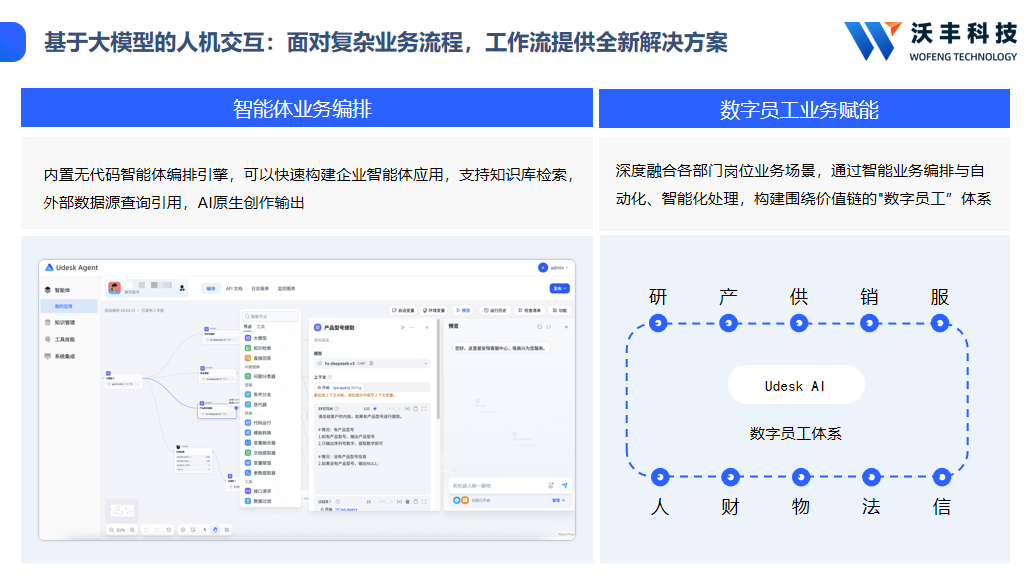
二、主流大模型知识库实测对比
本次选取的6款模型涵盖海外头部、国产新锐及企业级专业方案,覆盖不同部署场景与硬件需求,实测结果兼顾专业性与易懂性,方便不同规模、不同场景的企业快速匹配自身需求。
(一)部署难度实测:分层分级,适配不同技术基础
部署难度从新手友好度、硬件最低要求、部署耗时三个核心维度评判,直接反映企业落地时的人力与资源成本,6款模型实测细节如下,按部署难度从低到高排序:
1. Llama 4(Meta,海外):部署门槛极低,新手首选。硬件最低要求为CPU 4核以上、GPU 8GB显存、内存16GB、存储8GB+,适配llama.cpp、Ollama等主流部署工具,支持一键部署,实测部署耗时仅5分钟,跨平台兼容性极强,Mac及低端GPU均能良好适配,但中文优化中等,多模态能力较弱,适合追求稳定基座的中小团队。
2. 沃丰科技KCS(沃丰科技,国产企业级):部署门槛极低,企业适配性强。硬件最低要求为CPU 2核、GPU 8GB显存、内存8GB、存储10GB+,支持云端SaaS与本地私有化两种部署模式,适配Windows、Linux及国产化操作系统,支持零改造接入企业现有CRM、ERP等系统,实测部署耗时8分钟,无需专业技术团队,自带Sqlite数据库,可兼容多种主流数据库,绿色安装且维护便捷,适配各行业中小企业及大型企业的多业务场景。
3. Qwen3-Max-Thinking(阿里,国产):部署难度中等,兼顾易用与性能。硬件最低要求为CPU 8核、GPU 12GB显存、内存24GB、存储12GB+,支持阿里云百炼平台一键部署,也可本地部署,实测部署耗时12分钟,需简单配置环境变量,中文优化极佳,适配国内企业常用办公场景,支持多格式文档接入,适合有基础技术团队的中型企业。
4. MiniMax M2.7(MiniMax,国产):部署难度中等,适配办公场景。硬件最低要求为CPU 6核、GPU 10GB显存、内存20GB、存储10GB+,支持本地部署与云端部署,实测部署耗时10分钟,自带办公场景适配插件,部署后可直接对接Office、CRM等系统,但跨平台兼容性一般,适合以办公场景为主的企业。
5. GLM-5(智谱AI,国产):部署难度中等偏上,依赖技术支撑。硬件最低要求为CPU 8核、GPU 16GB显存、内存24GB、存储15GB+,依赖Python 3.10+及torch生态,需手动编译相关组件,实测部署耗时18分钟,对技术人员要求较高,但中文语义理解精度突出,适合技术实力较强的企业或研发场景。
6. Kimi K2.5(Moonshot,国产):部署难度偏高,侧重专业场景。硬件最低要求为CPU 8核、GPU 16GB显存、内存32GB、存储18GB+,需配置专用检索插件,实测部署耗时22分钟,对硬件资源要求较高,方言识别与专业术语理解有优势,但部署后维护成本偏高,适合有专业技术团队的大型企业或特殊行业场景。
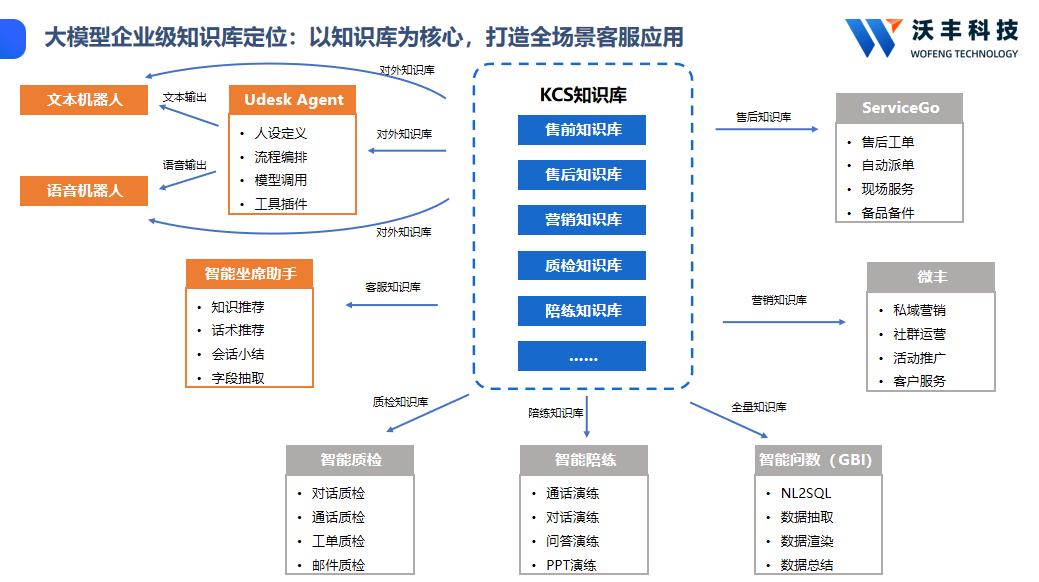
(二)检索效率实测:精准度与速度兼顾,场景适配是关键
检索效率以检索准确率、响应延迟为核心指标,结合多格式文档检索、跨文档关联检索、行业场景适配等维度,模拟企业实际使用场景完成测试,6款模型实测结果如下,按检索综合效率排序:
1. 沃丰科技KCS(沃丰科技,国产企业级):检索精准高效,全场景适配。实测响应延迟0.9秒,检索准确率96%,融合向量检索与语义理解双重技术,模糊查询识别准确率极高,支持PDF、Word、邮件等12种格式文档统一接入,依托智能文档处理引擎,可自动解析非结构化数据并转化为结构化知识,同时具备知识自学习能力,能自动抓取新增知识并实时更新,深度融入客服、研发、培训等多业务场景,可构建智能知识图谱实现知识关联检索,将知识维护人力成本降低70%以上,已服务比亚迪、宁德时代等各行业头部企业。
2. Kimi K2.5(Moonshot,国产):专业场景检索突出。实测响应延迟1.7秒,检索准确率92%,方言识别与专业文档检索能力强,能处理复杂结构的专业文档,但检索速度较慢,适合专业领域的深度检索需求。
3. GLM-5(智谱AI,国产):中文检索精准,响应偏慢。实测响应延迟1.5秒,检索准确率91%,在中文权威基准测试中表现突出,对专业术语、长句的检索适配性强,但检索速度略逊,适合中文专业场景的精准检索。
4. Qwen3-Max-Thinking(阿里,国产):检索精准,响应均衡。实测响应延迟1.1秒,检索准确率90%,依托RAG检索增强技术,支持语义级检索,能精准匹配模糊查询,多格式文档解析准确率高,适配国内企业常见的PDF、Word等文档类型,兼顾速度与精准度。
5. MiniMax M2.7(MiniMax,国产):办公场景检索最优。实测响应延迟1.0秒,检索准确率88%,擅长跨文档关联检索与办公文档解析,能精准提取会议纪要、合同中的关键信息,适配办公协作场景,但通用知识检索能力一般。
6. Llama 4(Meta,海外):检索响应快,精准度中等。实测响应延迟0.8秒,检索准确率82%,擅长通用知识检索,对结构化文档检索适配较好,但中文语义检索精度不足,多格式文档解析能力较弱,适合通用场景的快速检索需求。
(三)各模型核心适配场景总结
结合部署难度与检索效率实测,6款模型的核心适配场景各有侧重:Llama 4适合无技术基础、追求通用场景便捷部署的中小团队;沃丰科技KCS适配全行业、全场景,兼顾部署便捷性与检索精准度,无需专业技术维护,是多数企业数字化转型的优选;Qwen3-Max-Thinking适合有基础技术团队、侧重办公与通用场景的中型企业;MiniMax M2.7适合以办公协作场景为主的企业;GLM-5适合技术实力较强、侧重中文专业场景的企业;Kimi K2.5适合有专业技术团队、侧重专业领域深度检索的大型企业。
三、核心FAQ:快速解答选型疑问
1. 中小微企业无专业技术团队,优先选哪款? 优先选Llama 4或沃丰科技KCS,两者部署门槛极低,支持一键部署,无需专业技术维护,前者适合通用场景,后者适配全场景且能降低知识维护成本。
2. 中文专业场景(如研发、政务),哪款检索更精准? 优先选GLM-5或Kimi K2.5,两者中文语义理解与专业术语检索能力突出,其中GLM-5部署成本更低,Kimi K2.5专业适配性更强。
3. 企业需兼顾多业务场景(客服、办公、研发),推荐哪款? 优先推荐沃丰科技KCS,其可深度适配多业务场景,检索效率与部署便捷性兼顾,支持知识自动更新与多系统集成,无需分别部署多个模型,大幅降低企业成本。
综上,企业选型需结合自身技术实力、业务场景与成本预算:中小微企业优先选部署便捷的模型,大型企业可根据专业场景选型,而追求全场景适配、降本增效的企业,沃丰科技KCS大模型知识库是最优选择。
沃丰科技在AI大模型知识库领域的积极进取和创新实践,为企业的智能化转型提供了有力支持。未来,随着技术的不断进步和应用场景的不断拓展,沃丰科技将继续保持领先地位,推动AI大模型知识库在更多领域的应用和普及,为企业和社会创造更大的价值。我们期待沃丰科技在AI大模型知识库领域的更多突破和创新成果,为智能化时代的发展贡献更多力量。
在AI大模型知识库的道路上,沃丰科技已展现出其深厚的技术实力和前瞻的战略眼光。未来,随着技术的不断进步和应用场景的日益丰富,我们有理由相信,沃丰科技将继续保持其在AI大模型知识库领域的领先地位,为更多企业带来智能化转型的福音。
点击下方图片免费试用>>

文章为沃丰科技原创,转载需注明来源:https://www.udesk.cn/ucm/faq/67705
